- Inicio
- ⟩
- Tecnología
- ⟩
- Tras las pepitas de oro de la información: la minería de textos en la UNAM
Tras las pepitas de oro de la información: la minería de textos en la UNAM
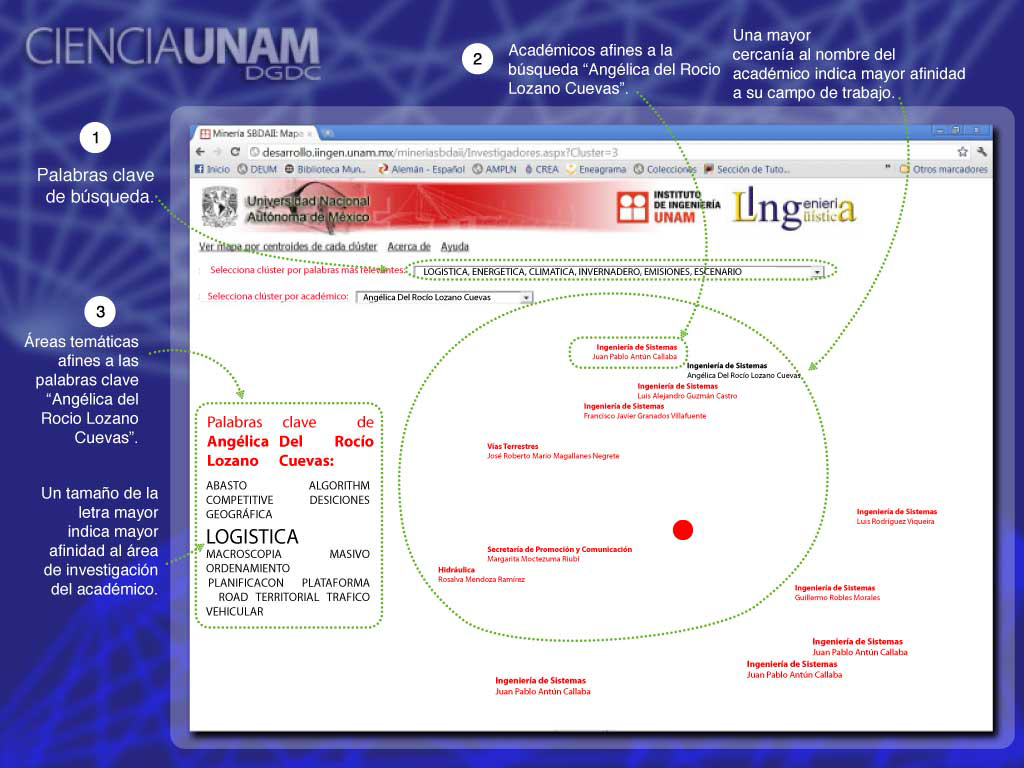
Interfaz de la herramienta informática desarrollada en el IINGEN-UNAM. Gráfico: Natalia Rentería.
05-03-2012
Por Sacbel Monsiváis Molina DGDC-UNAM




Se dice que hay “oro” escondido en las montañas de documentos que cualquier empresa o institución genera diariamente: información valiosa enterrada en cada texto y que, de ser extraída, serviría, por ejemplo, para hacer análisis de rentabilidad, identificar competencias, monitorear el mercado e incluso detectar fraudes.
Sin embargo, leer y analizar esa enorme cantidad de texto en poco tiempo sería, además de tortuoso, humanamente imposible. Por ello es necesario instrumentar mecanismos que procesen los documentos de manera eficaz y automática. Esto se puede lograr mediante la minería de textos.
Mientras que la minería tradicional explota montañas para encontrar vetas de metales preciosos, la minería de textos explora una inmensa cantidad de archivos con el objetivo de extraer información útil. Este campo, relativamente nuevo, es un área de la ingeniería lingüística, disciplina que combina los conocimientos sobre la estructura del lenguaje humano con sistemas informáticos, de manera que sea posible reconocer, comprender, interpretar y generar lenguaje escrito u oral.
Con la minería de textos, el Grupo de Ingeniería Lingüística (GIL) del Instituto de Ingeniería de la UNAM (IINGEN) desarrolló dos herramientas informáticas para explorar la montaña de documentos que generan sus académicos, y ya extrajo sus primeras “pepitas de oro”.
Estas tecnologías son producto del proyecto “MBDAII: Minería de textos sobre el sistema de base de datos académica del Instituto de Ingeniería”, destinado a conocer el desempeño y las competencias del cuerpo académico de dicha dependencia, para impulsar su crecimiento.
Herramientas para explorar textos
Las dos herramientas son un agrupador y un recuperador de académicos. La primera busca conjuntos de académicos similares, es decir, investigadores que trabajen en temas parecidos. La segunda herramienta permite encontrar aquellos investigadores cuyos documentos respondan a las peticiones específicas de información que el usuario formule. Por el momento, los programas son de uso interno y a ellos sólo tienen acceso los académicos y la directiva del IINGEN.
Alfonso Medina Urrea, investigador asociado del GIL, explicó en entrevista que, al comparar las áreas de investigación detectadas mediante el agrupador de académicos, con el conjunto de subdirecciones y coordinaciones de investigación del Instituto (declaradas o establecidas previamente), él y su grupo se percataron de que no existía una total correspondencia entre ellas.
Según Medina, “hay coordinaciones que trabajan con temas tan similares que podrían ser una misma, o hay investigadores dentro de una coordinación que en realidad deberían de pertenecer a otra”. Asimismo, dijo que es posible encontrar grupos de académicos que sobresalgan por ser únicos.
En cuanto al recuperador de académicos, Medina ofreció un ejemplo: “Si yo quiero saber qué académicos del Instituto de Ingeniería se ocupan de los terremotos en el estado de Guerrero, puedo hacer una petición de búsqueda”.
Un nuevo tipo de minería
Para obtener la información valiosa de las montañas de documentos, la minería de textos consta, como la minería tradicional, de una serie de etapas.
Mientras que en la minería tradicional la etapa de prospección establece, mediante equipos especializados de detección, los sitios susceptibles a la explotación minera, la minería de textos delimita su yacimiento recopilando los documentos que se quieren procesar, aún cuando no se conozca la información que de ellos se obtendrá. El GIL, por ejemplo, compiló los informes anuales y publicaciones (como artículos científicos y capítulos de libros) generadas por los investigadores. También incluyó información contenida en la base de datos del Instituto, como los títulos de las tesis dirigidas y las notas de ponencias.
En la siguiente etapa, conocida como de exploración, se prepara el yacimiento, la extracción y el transporte de los minerales. En el caso de la minería de textos, lo que se hace es pre-procesar los documentos para poder manipularlos; primero se estandarizan en un mismo formato electrónico y después, mediante algoritmos, el texto se fragmenta en partes más sencillas. Esto sirve para identificar las palabras representativas o clave de cada documento.
En la etapa siguiente, de explotación y beneficio, se purifican los minerales extraídos para elevar su contenido útil. Aquí, el GIL toma los rasgos de cada texto y construye matrices o tablas, una por cada académico. A partir de las matrices se aplicaron algoritmos de agrupamiento que, bajo ciertos criterios previamente establecidos por el GIL, descubren las coincidencias y asociaciones existentes entre las matrices.
Según explicó Medina Urrea, los agrupamientos emergen naturalmente; cada agrupamiento está caracterizado con palabras clave que lo distinguen respecto del resto. Por ejemplo, un determinado agrupamiento estaría caracterizado por las palabras clave: vehicular, óptica y bomba. Es en esta etapa durante la cual se descubrieron la cantidad y el tipo de áreas de conocimiento que había dentro del Instituto.
Minería todo terreno
El investigador recalcó que el panorama sobre las áreas de investigación del IINGEN arrojado por la minería de textos, es sólo descriptivo, pues se necesitan más criterios a considerar para cambiar la organización y estructura actual de la dependencia. Además, dijo, es posible que no toda la información de un académico esté considerada en el proceso.
No obstante, Medina Urrea admitió que sí podría incidir en algunas de sus actividades. Por ejemplo, el IINGEN provee de servicios a dependencias públicas, como PEMEX, y privadas, como la compañía constructora Ingenieros Civiles Asociados (ICA). A través del instituto universitario ingresan a la UNAM importantes cantidades de dinero, y por ello, “se debe promover para que se conozca qué es lo que [el IINGEN] puede ofrecer”.
El GIL aún perfecciona sus dos herramientas informáticas, para obtener información más precisa. “Lo importante es que pueden utilizarse para procesar las muchas otras bases de datos de la UNAM, y los muchos documentos que se generan a diario solo para su funcionamiento”, apuntó Medina.
El GIL planea presentar este año a la comunidad universitaria la versión final del MBDAII. “Será un programa que cada año pueda correrse para que sean procesados todos los nuevos investigadores, o todos los nuevos trabajos; además de que cada año la base de datos se actualiza”, agregó el investigador.

Publicaciones relacionadas

¿Buscas información sobre Ciberseguridad?

Minería en mar profundo ¿nueva fiebre del oro?

Especial Coronavirus ¿Buscas información de COVID-19 y otras enfermedades virales?












Enrédate
![]()
![]()
![]() Síguenos en nuestras redes sociales
Síguenos en nuestras redes sociales